Tetsuro Kitahara Research Overview
Sorry for not being translated into English in part.
Motivation and Aim
One of the major functions lacking in the current computing technology
is recognition of the real world.
Humans use various information obtained from the real world through
their eyes and ears to judge situations and appropriate behavior
in everyday life.
Computers' capability to recognize auditory and visual scenes
is, however, strictly limited.
In particular, there have been relatively few
attempts to investigate sound recognition,
except speech recognition studies.
Techniques for recognizing a variety of sounds, not limited to speech,
will be important to realize sophisticated computers that
extensively use the real-world information.
One major reason why it is difficult for computers to recognize
auditory scenes is that the auditory scenes in the real world usually contain
multiple simultaneous sources of sound.
Because conventional speech recognition studies have assumed that the input
sounds to be recognized are voices spoken by a single speaker,
they did not deal with situations where multiple sources simultaneously
present sound.
Although there have been a number of attempts
to recognize speech
under noisy environments,
the number of the source to be recognized is always one;
the other sound sources are regarded as noise.
We focus on polyphonic music as a target domain of the research into auditory scene recognition. The key point in developing a computational model of auditory scene recognition is predictability. It is often said that music is enjoyable because we can predict how the music unfolds to some extent but cannot perfectly predict it. Our goal is to develop, using probabilistic models such as Bayesian networks, a computer system that listens to music by predicting music.
Three Issues
We have to resolve three issues in achieving this predictive music listening model.
The first issue is signal processing for mixtures of multiple simultaneous sounds. We plan to develop signal processing techniques by extending our musical instrument recognition method based on Instrogram for polyphonic music. Instrogram is a probabilistic representation of what instrument sounds at what time in what pitch. This can be calculated through hidden Markov models prepared for each half note.
The second issue is prediction models for various abstraction levels of music representations. Music is represented in various levels of abstraction: frequency components, notes, chord symbols, and global music structures. Prediction models for each of such abstraction levels should be performed in parallel because they may be mutually dependent.
The third issue is a framework for implementing such signal processing techniques and prediction models. This framework should enables us to easily reuse existing processing modules and integrating them in order to effciently develop a complicated system. We have therefore been develping CrestMuseXML, an extensible framework for XML-based music description, and the CrestMuseXML Toolkit, an open-source library provides common APIs to access various music descriptions.
Furthermore, we are engaged in music information retrieval and musical performance support.
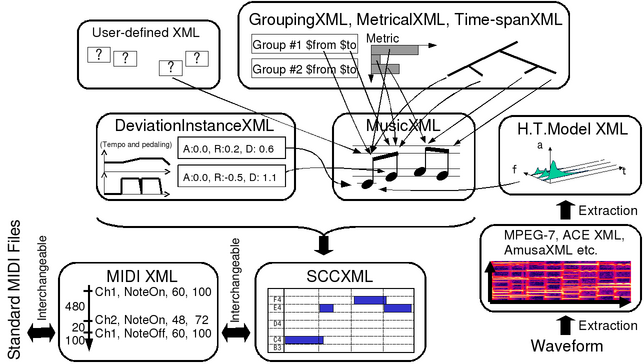
Although many music information processing systems have been developed, it is not easy to integrate them because representations of music data are different. To solve this problem, we developing a unified framework for describing music data, CrestMuseXML, and its open-source toolkit.
References
-
�$BKL86�(B �$BE4O/�(B,
�$BJR4s�(B �$B@290�(B:
"CrestMuseXML (CMX) Toolkit ver.0.40�$B$K$D$$$F�(B",
�$B>pJs=hM}3X2q�(B �$B2;3Z>pJs2J3X�(B �$B8&5fJs9p�(B,2008-MUS-75-17, Vol.2008 , No.50, pp.95--100, May 2008.
[Paper in pdf]
-
�$BKL86�(B �$BE4O/�(B,
�$B66ED�(B �$B8wBe�(B,
�$BJR4s�(B �$B@290�(B:
"�$B2;3Z>pJs2J3X8&5f$N$?$a$N6&DL%G!<%?%U%)!<%^%C%H$N3NN)$rL\;X$7$F�(B",
�$B>pJs=hM}3X2q�(B �$B2;3Z>pJs2J3X�(B �$B8&5fJs9p�(B,2006-MUS-66-12, Vol.2007, No.81, pp.149--154, August 2007.
[External Link]
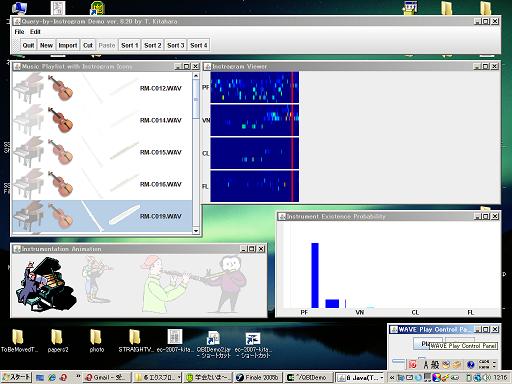
We often have different impressions when listening to the same musical piece played on different musical instruments. This implies the importance of information about instrumentation (on what instruments a musical piece is played) as a factor of music information retrieval (MIR). We have developed a MIR system that searches for musical pieces that have similar instrumentation to that of the piece specified by the user.
This system has been achieved by using a musical instrument recognizer based on Instrogram, a time-frequency representation of instrument existence probabilities. We are also engaged in applications of instrograms to music visualization and music entertainment.
References
-
Tetsuro Kitahara,
Masataka Goto,
Kazunori Komatani,
Tetsuya
Ogata,
and
Hiroshi
G. Okuno:
"Instrogram: Probabilistic Representation of Instrument Existence for Polyphonic Music",
IPSJ Journal,
Vol.48, No.1, pp.214--226, January 2007.
[Paper in pdf]
(�$BBh�(B3�$B2s�(BIPSJ Digital Courier�$BA%0f)Ne>^�(B)(also published in IPSJ Digital Courier Vol.3, No.1, pp.1--13)
[External Link]
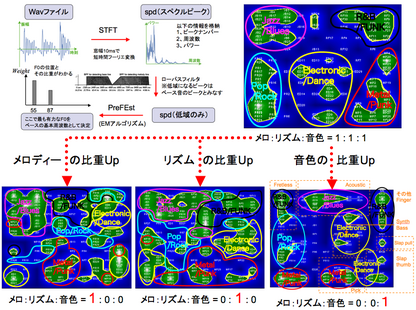
Spectral and cepstral features, which are commonly used in content-based music information retrieval (MIR), are useful and powerful features but they do not capture the characteristics of the content of music enough because all they directly represent is a frequency characteristic. To further improve MIR, we have to develop features that directly represent various aspects of music. To design such features, we have focused on the bass part, which play important roles in both rhythm and harmony, and have been engaged in the design of bass-line features and its application to content-based
References
- Yusuke Tsuchihashi,
Tetsuro Kitahara,
and
Haruhiro Katayose:
"Using Bass-line Features for Content-based MIR",
Proceedings of
the 9th International Conference on Music Information Retrieval
(ISMIR 2008),
pp.620--625, September 2008.
[Paper in pdf]
�$B<+F0:n6J!$<+F0JT6J!$3Z6J2rpJs=hM}%?%9%/$O!$3,AXE*2;3ZI=8=%M%C%H%o!<%/$K$*$1$k4{CN$N%N!<%I$+$iL$CN$N%N!<%I$N?dO@$H9M$($k$H!$F1$8%b%G%k$G@bL@$9$k$3$H$,$G$-$^$9!%K\8&5f$G$O!$3FpJs=hM}%?%9%/$r9T$&E}0lE*%"!<%-%F%/%A%c$Ne$2!$%?%9%/$4$H$N2]Bj$N@v$$$@$7$r9T$C$F$$$^$9!%�(B
References
- �$B>!@j�(B �$B??5,;R�(B,
�$BKL86�(B �$BE4O/�(B,
�$BJR4s�(B �$B@290�(B,
�$BD9ED�(B �$BE5;R�(B:
"�$B%Y%$%8%"%s%M%C%H%o!<%/$rMQ$$$?%3!<%I!&%t%)%$%7%s%0?dDj%7%9%F%`�(B",
�$B>pJs=hM}3X2q�(B �$B2;3Z>pJs2J3X�(B/�$B2;@<8@8l>pJs=hM}�(B �$B8&5fJs9p�(B,
2008-MUS-74-29, 2008-MUS-SLP-70-29, Vol.2008, No.12, pp.163--168, February 2008.
�$B%f!<%6$NB(6=1iAU$r4F;k$7!$2;3ZE*$KITE,@Z$+$I$&$+$rH=Dj$7!$ITE,@Z$J$iB>$N2;$KJd@5$9$k$H$$$&?7$?$J1iAU;Y1g%7%9%F%`$r3+H/$7$^$7$?!%$3$l$^$G$KMM!9$J1iAU;Y1g8&5f$,$"$j$^$7$?$,!$B(6=1iAU$r07$C$?$b$N$O>/$J$/!$!V3Z4o1iAU7P83$O$"$k$,!$B(6=1iAU$OI_5o$,9b$$!W$H$$$&J}!9$KBP$7$F$=$NI_5o$rDc$/$7!$B(6=1iAU$N3Z$7$_$r/2;3ZE*$KIT<+A3$J@{N'$rCF$$$F$b%9%T!<%+!<$+$i$O2;3ZE*$K<+A3$J@{N'$,=PNO$5$l$^$9$N$G!$=i?4
References
-
Katsuhisa
Ishida,
Tetsuro Kitahara,
and
Masayuki Takeda:
"ism: Improvisation Supporting System based on Melody Correction",
Proceedings of the International Conference on New
Interfaces for Musical Expression
(NIME 2004),
pp.177--180, June 2004.
[Paper in pdf]
-
Tetsuro Kitahara,
Katsuhisa
Ishida,
and
Masayuki Takeda:
"ism: Improvisation Supporting Systems with Melody Correction and Key Vibration",
Entertainment Computing: Proceedings of the 4th International Conference on
Entertainment Computing (ICEC 2005),
Lecture Notes in Computer Science 3711, F. Kishino, Y. Kitamura, H. Kato and N. Nagata (Eds.), pp.315--327, September 2005.
[Paper in pdf]
[External Link]